接續昨天的進度
從Autoencoder 開始,昨天產生的watercolor就有用到
那我們來看一下這個是什麼
這邊主要從筆記本中的進度做簡略介紹,要了解較清楚的話,先看完以下兩個影片
李宏毅autoencoder 1 2
自動編碼器是什麼,它的目的是什麼?
自動編碼器是一種神經網絡,它的目的是學習一個數據的有效表示。它由兩部分組成:編碼器和解碼器。編碼器的工作是將輸入(如圖像)壓縮成一個潛在的、通常較小的表示,而解碼器則將這個表示轉換回原始的輸入。
那這種學習的表示有什麼好處呢?
當有一個有效的數據表示時,可以使用它來完成各種任務,例如圖像生成、分類或者壓縮。
以下我們會先寫2個function,把圖片做轉換成潛在表示(latent),再把latent 轉換回圖片
pil_to_latent(input_im)
這個函數將PIL圖像轉換成其潛在表示。PIL是Python Imaging Library的縮寫,它是Python中用於圖像處理的一個主要庫。
在這裡,我們的目的是獲得圖像的一個更簡潔、更抽象的表示,這將允許我們在潛在空間中進行操作,而不是直接在圖像像素上操作。
latents_to_pil(latents)
這個函數則是進行相反的操作,將潛在表示轉換回PIL圖像。
當我們在潛在空間中完成所需的操作後,我們需要一種方法將其轉換回圖像,以便我們可以視覺化結果或進行其他後續處理。
def pil_to_latent(input_im):
with torch.no_grad():
latent = vae.encode(tfms.ToTensor()(input_im).unsqueeze(0).to(torch_device)*2-1) # Note scaling
return 0.18215 * latent.latent_dist.sample()
torch.no_grad()確保在此計算過程中不計算任何梯度,因為我們只是進行前向傳播,不需要反向傳播的梯度。
tfms.ToTensor()(input_im)將PIL圖像轉換為PyTorch張量。這是一個常見的轉換,將圖像數據轉換為可以供模型處理的形式
unsqueeze(0)在數據的第一個維度添加一個額外的維度,通常是批次維度。這意味著我們正在處理一個批次的圖像,即使只有一張圖片。
*2-1是對張量的數據進行縮放。這種縮放在處理圖像數據時很常見,目的是將數據範圍從[0,1]轉換到[-1,1]。
vae.encode(...)將處理後的圖像數據通過自動編碼器的編碼部分,得到潛在表示。
latent.latent_dist.sample():這部分從潛在分佈中抽取一個樣本。當我們編碼圖像時,我們不只是得到一個潛在向量,而是得到一個潛在分佈。這是因為自動編碼器(特別是變分自動編碼器)試圖學習一個分佈,而不只是一個固定的潛在向量。從這個分佈中抽取樣本意味著我們得到了一個具體的潛在向量,我們可以使用它來解碼或進行其他操作。
def latents_to_pil(latents):
latents = (1 / 0.18215) * latents
with torch.no_grad():
image = vae.decode(latents).sample
...
return pil_images
(1 / 0.18215) * latents對潛在表示進行縮放。這是為了反轉之前進行的縮放操作,確保數據在正確的範圍內
使用torch.no_grad()再次確保不計算梯度
vae.decode(latents).sample將潛在表示通過自動編碼器的解碼部分,得到重建的圖像
接下來的code處理將解碼後的圖像張量轉換為PIL圖像的格式,以便於可視化或其他後續操作
然後接下來講師就download 了一張macaw的圖片來展示,我們也跟著下載
然後呼叫我們的編碼函式
# Encode to the latent space
encoded = pil_to_latent(input_image)
encoded.shape
# output is torch.Size([1, 4, 64, 64])
可以看到有四個通道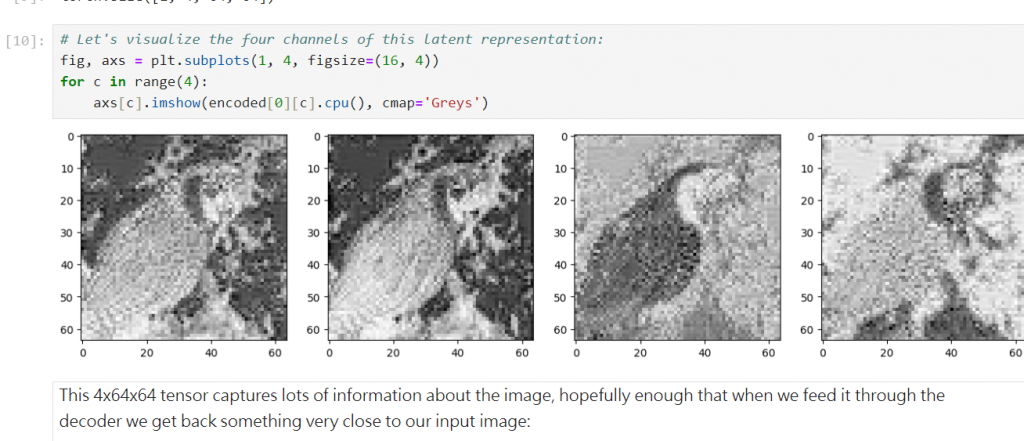
潛在表示的可視化有助於我們理解自動編碼器的工作方式。特定的通道可能會捕獲圖像中的特定特徵或結構。通過檢查這些潛在通道,我們可以獲得關於模型如何「看待」和「解讀」輸入圖像的直觀了解。這也可以幫助我們評估模型的效能,看看它是否成功地將主要的圖像特徵編碼到這些潛在通道中
那再解碼回來看看
decoded = latents_to_pil(encoded)[0]
decoded
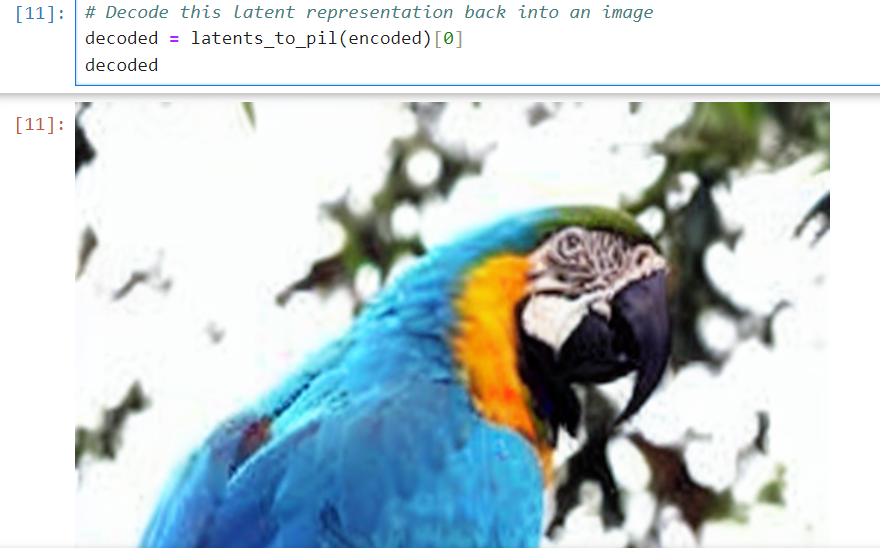
我們觀察一下筆記本中,encode 前/ 後的圖片,會發現一些細微的差異
但這個可以讓我們的計算量大幅降低,(對於直接在image 上面操作),所以我們如果在潛在空間上面
計算出了新圖像,隨時可以decode 回來。


 iThome鐵人賽
iThome鐵人賽